


豆包开云体育,不错视频通话了。
自岁首更新「及时语音通话」功能之后,这一功能就抓续受到用户接待。当今在酬酢媒体上搜索豆包,排行前十的热点要津词中,有 6 个与「打电话」功能相干。大王人和豆包通话相干的创意内容也受到了不雅众追捧。
跟着视频才略上线,豆包的通话功能迎来了一次「升维」,变得更实用、好用。聚拢视频图像,许多即便暗昧的语音输入,也能够更好地被 AI 领悟,用户不需要再组织语言去刻画目下的信息。
视频通话是一个单点功能,但在这背后是语言才略、多模态才略、推理才略、学问库等等多个垂直限制的工夫蕴蓄、整合,以及对老本和后果的均衡。
更紧迫的是,视频通话才略预示了 AI 助手更远的出路。当 AI 同期领有了眼睛和耳朵,在过去更多硬件改造的撑抓下,还将自如更大的改造后劲。
01
帮你领悟目下一切的豆包
视频通话才略给豆包带来的,当先是多模态领悟的才略提高和交互优化。
从最基础的「领悟」场景启动,用户不错把手机录像头瞄准任何信息,如信息版、菜单,让豆包给出翻译、讲解。何况历程中,用户不错抑止通过语言输入,来修正豆包的关提防心。
比如在一个博物馆里,当咱们开启视频通话,问豆包这是什么,豆包当先会证据画面里的地标特征,识别出这是「新加坡国度好意思术馆」。然后咱们要是无间追问,楼上挂着的横幅是什么道理,豆包又会给出具体展览信息的翻译和讲解。
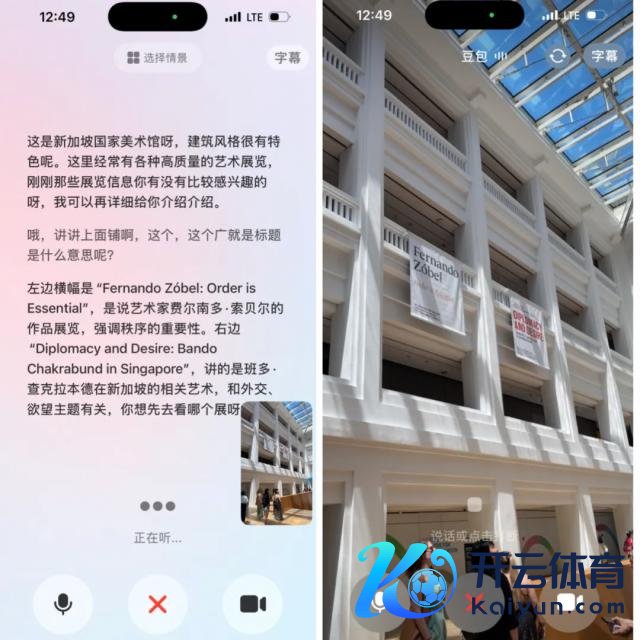
而在看展览的历程中,咱们也不错举入部下手机,随时针对任何一幅作品向豆包提问。从基本的翻译作品信息,到问它作品格调具体属于哪一个流派,是否有师法哪个艺术家的陈迹,豆包王人能给出精确判断。
基于豆包给出的信息,咱们也能进一步挖掘一些更深的遮蔽关联。比如在新加坡国度好意思术馆里有一个法院拘留室的展示区域,问过豆包之后我发现,这里的关系在于,新加坡国度好意思术馆由原政府大厦和原最高法院大楼改建而成。前法院的拘留室曾用于关押候审的被告,在好意思术馆改建后,部分拘留室被保留了下来,成为了好意思术馆的一部分,供公众参不雅,让东说念主们不错了解新加坡的端正历史。

除此以外,咱们还不错和豆包讲讲我方对好意思术作品的一些领悟和见识,进行不雅点碰撞。本体上,豆包一经具备一定的「纠错」才略,不是只会一味地依从用户的领悟。比如这里,当我援用了失误的类比,说这个作品像「蒙德里安」格调时,豆包能够改造我的失误,告诉我本体像的是安迪 · 沃霍尔。之后咱们还不错进一步酌量,为什么会出现这个失误。咱们也不错勾搭豆包对作品进行批判性的解读和评价。
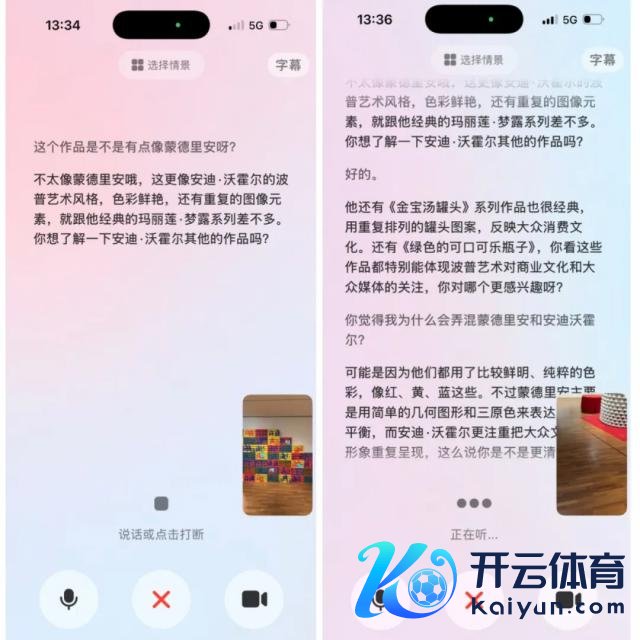
这里还有一个很要津的点,因为有了图像视觉信息算作扶助,许多时候即便我发出教唆的声息很小,豆包并未无缺识别我所说的句子的每一个字,但它依然能通过捕捉要津词,准确领悟我的意图。
在旅行、不雅光、展览……等视觉信息占比更高的场景,最能体现出豆包视频通话才略的上风。咱们不错顺手举起手机,让豆包看到咱们目下的东西,从最基本的「这是什么?」开赴,少许点挖掘出更多的信息和学问。比如让豆包证据相近的酣畅推理出咱们在哪,推选相近值得一去的景点、步履、特点饮食,这既具有实用价值也充满乐趣,稳健出游不可爱作念严实的计较,可爱碰到更多只怕惊喜的 P 东说念主。

包括在餐厅吃饭,碰到那些「不知说念该怎样吃」的情形,也很稳健通过视频通话功能乞助豆包。比如吃荞麦面的时候伴计端上来一壶像沸水相通的东西,这个时候豆包也松驰给出了正确谜底,壶里装的是荞麦面汤,不错和酱汁搀杂在沿途喝掉。

豆包的视频通话功能,比较芜俚的图像识别,最要津的上风依然在于它的「互动性」更强。基于单张图像的领悟和推理,很可能出现各式领悟偏差、失误。有了视频形式之后,即便豆包给出了一个比较可疑的回复,咱们也不错通过换个角度,提供更多信息,来给豆包进行更多想考和修正的契机。
比如在这个场景下,咱们想知说念酒店的某个安装的作用,问豆包之后它当先认为咱们问的是前边的熨衣板。经过进一步交互,它知说念了咱们想问的是后头的行李架,但因为角度问题,它将行李架失误领悟成了健身器材,之后换个角度进一步追问并识别之后,豆包到手给出了行李架这一谜底。

这是视频通话的功能的要津上风之一。当下任何 AI 大模子王人不成幸免地会有「幻觉」和失误。当用户全心编写了一大段 prompt 却莫得取得我方想要的输出驱逐时,就会极大打击他们使用 AI 的积极性。但通过给到更多信息,提供更多角度的输入补充,就能让 AI 更接近咱们需要的正确谜底。不错说,在视频通话场景下,AI 和用户酿成了互动的正向轮回。
除了普通生涯场景,豆包的视频通话功能还不错在学习、责任等各式场景证实作用,畸形是基于一些纸质的材料进行领悟和修改。比如对多页的纸质贵府进行追忆,或对学科题目进行解答、纠错。
02
模子工夫的「木桶表面」
「视频通话」的功能自身相称简陋,任何用户领悟起来王人莫得门槛,但在这背后,其实需要复杂的工夫算作撑抓。
豆包视频通话功能的中枢来自「豆包视觉领悟模子」的撑抓。2024 年 12 月,豆包初次发布视觉领悟模子,为视频通话功能提供了模子才略基础。
除了视觉感知以外,豆包视觉领悟模子还具备深度想考才略。这让豆包本体上还不错通过录像头径直进行解学科题目、分析论文以及会诊代码等任务。这亦然为什么在视频通话历程中豆包能同期聚拢「图像画面」和「用户语音教唆」,精确领悟用户意图。
豆包并不是第一个扫尾这一功能的 AI 助手,但想要同期领有优秀的视觉领悟才略,再基于视觉领悟和用户教唆,将不同模态的信息概述领悟后,生成用户想要的信息,同期还要作念到低蔓延,这一切就有很高的工夫门槛。
通盘历程有点像「木桶表面」,一个模子必须同期作念好多个方面,材干作念到像一个委果的「AI 助手」相通,称心用户的需要。
03
为什么「视频通话」能解锁 AI 交互的更多改造?
今天,「视频通话」仅仅豆包的一个小功能。但本体上,视觉领悟才略所蕴含的后劲和可能性还不啻于此。
自降生于今,大模子 AI 助手的交互王人是「一问一答」式,用户输入 prompt,AI 生成反应。这里最大的矛盾在于,整理编写 prompt 是有门槛的,且这个门槛比联想中更高,而一问一答式的交互又是断裂的,行家王人很容易「把天聊死」,靠近 AI 也相通。
而视觉图像的引入,则为东说念主机交互建设了一个「语境」,且这个语境的建设不需要任何门槛,自然富含信息,用户只需要举起录像头就行了。本体上,东说念主类自身领悟寰宇的历程中,咱们最紧迫的信息给与器官也一直是眼睛。
通过豆包的视频通话功能,这一形式的灵验性一经取得体现。通过连贯的互动加上视觉领悟,用户和 AI 交互的历程变得更当然了,不错通过抑止补充、讲解,来接近我方想要的阿谁贪图。这种用户和 AI 相互勾搭,对 propmt 进行抑止修正,能极大加多 prompt 输入的带宽和精确度。
本体上,这早即是行业共鸣。自 AI 大模子工夫降生之后,险些所有硬件改造王人是在探索一种「录像头 + 麦克风」的组合,从 AI Pin,到各式 AI 智能眼镜,王人是在建设一种让 AI「看 + 听」的感知形式。只不外目前大部分这类硬件,王人还无法在性能和后果上,作念到像手机那么高的可行度。
当下咱们在使用豆包的视频通话功能时,依然能感受到它被手机这个硬件载体适度着。比如咱们很难万古刻举入部下手机瞄准前线咱们看到的东西,以及在一些环球场所也未便于高声话语,无法和 AI 充分进行语音疏浚,这王人是智高手机算作传统硬件的适度场所。
从豆包的「视频通话功能」一经不错看出,让 AI「看 + 听」的输入形式开云体育,可能代表 AI 交互的更多可能性。它在软件上所有是可行的,跟着模子才略的进一步发展,聚拢硬件改造,概况将进一步改变咱们与 AI 的交互面目。